
モデルの学習とは、蓄積したデータをもとに統計的・数理的なパターンを抽出し、未知の入力に対して高い精度で予測や分類を行える仕組みを作り上げる工程です。
これを自社の業務フローに組み込むことで、需要予測の精度向上や異常検知の自動化など、意思決定のスピードと品質を同時に引き上げる効果が期待できます。
一方で、学習用データの品質が低かったり、過学習を見抜く体制が整っていなかったりすると、モデルが本番環境で機能しないばかりか、コストだけが膨らむリスクもあります。投資の成果を最大化するには、適切なデータ準備、アルゴリズム選定、運用モニタリングを一貫して行うことが欠かせません。
そこで本記事では、モデルの学習の基礎から、開発プロセス、代表的な学習手法とアルゴリズム、精度向上とコスト最適化のポイントまでを網羅的に解説します。
モデル活用でビジネスインパクトを高めたい方は、ぜひご一読ください。
【早見表】生成AIサービス主要20選(2025年版)【社内共有OK】
目次
モデルの学習(Training)とは
モデルの学習(Training)とは、蓄積したデータをもとに統計的・数理的なパターンを抽出し、未知の入力に対して精度高く予測・分類できる「モデル」を構築する工程を指します。
言い換えれば、データという経験をモデルに覚えさせ、再現性のある意思決定を自動化する仕組みをつくる作業です。ビジネスの現場では、需要予測・不良品検知・レコメンドなどに活用され、人的判断のスピードと品質を飛躍的に向上させる原動力になります。
学習と推論の違い
学習(Training)はモデルが知識を獲得するフェーズ、推論(Inference)は獲得した知識を使って実際に予測を行うフェーズです。学習では膨大なデータと計算資源を投入しモデルのパラメータを最適化します。
一方、推論は確定したパラメータを使うため計算負荷が小さく、リアルタイムでの応答や組み込みアプリケーションでの利用が可能です。この区別を理解することは、システム設計やコスト管理の観点で欠かせません。
モデル学習がビジネスにもたらす価値
モデルを自社課題に合わせて学習させると、属人的な経験や勘に依存せず、データ裏付けのある判断軸を社内に共通化できます。
たとえば営業パイプラインの成約確度を数値化したスコアリングモデルを導入すれば、限られたリソースを成果につながりやすい案件へ集中でき、売上と顧客体験の双方を改善できます。
また、継続的なデータ追加と再学習を行うことで、モデルが環境変化に追随し続けるというサイクルも構築できるため、中長期的な競争優位の確立につながります。
モデルの学習プロセス5ステップ
モデル開発を成功させるには、単発の実装ではなく「課題定義から運用まで」を一貫した流れで捉えることが不可欠です。
本章では、ビジネス現場で汎用的に使える5つのステップを紹介します。
1.課題定義と評価指標の設定
最初に行うのは、解決したい業務課題を具体的な目的変数と評価指標に落とし込む作業です。
たとえば「解約率を下げたい」という要望を「翌月の解約有無を二値分類し、F1スコアを最適化する」といった形に定義します。
ここで定義が曖昧だと、以降のデータ収集やアルゴリズム選定がぶれ、精度向上のための改善サイクルが回りません。経営層や現場担当と合意形成しながら、達成すべきKPIと許容コストを明確にすることが肝要です。
2.データ収集・前処理
課題が定まったら、モデルに学習させるデータを集めます。社内システムのログや外部APIなど、複数ソースを統合するケースが一般的です。
収集後は欠損値補完、外れ値除去、型変換、正規化といった前処理を施し、アルゴリズムが学習しやすい構造に整えます。この段階でデータ品質を徹底的に高めると、学習後の精度向上や再現性の確保に大きく寄与します。
3.モデル選定とハイパーパラメータ設計
次に、目的とデータの性質に合ったアルゴリズムを選びます。線形モデルで十分な場合もあれば、勾配ブースティングやニューラルネットワークが必要になる場合もあります。
選定後は、学習率・木の深さ・層数などのハイパーパラメータを設計します。自動最適化ツール(Bayesian Optimizationなど)を活用することで、試行錯誤の工数を抑えつつ最適解に近づけます。
4.学習とチューニング
モデルにデータを与えてパラメータを学習させ、検証データで性能を測定します。
過学習を防ぐためにクロスバリデーションで汎化性能を評価し、必要に応じて正則化やドロップアウトを適用します。
また、特徴量の追加・削除やハイパーパラメータの微調整を通じて反復的にブラッシュアップし、業務要件を満たす水準まで精度を高めます。
5.デプロイと継続的モニタリング
精度が安定したら本番環境へデプロイし、リアルタイムまたはバッチで推論を提供します。
運用開始後は、データ分布の変化や概念ドリフトを検知できるモニタリング基盤を整備し、パフォーマンスが低下したタイミングで再学習をトリガーします。
この継続的学習ループにより、モデルはビジネス環境の変化に追随し続け、ROIを維持・向上させます。
主な学習手法(教師あり・教師なし・強化学習)
モデルをビジネス課題に適用する際は、どの学習手法が目的に最も合うかを見極めることが重要です。ここでは「教師あり学習」「教師なし学習」「強化学習」という3つの代表的アプローチの特徴や適用シーンについて解説します。
| 着目点 | 教師あり学習 | 教師なし学習 | 強化学習 |
|---|---|---|---|
| データに必要な情報 | ラベル付きデータ | ラベル不要 | 状態・行動・報酬 |
| 主な目的 | 予測・分類 | 構造発見・異常検知 | 行動最適化 |
| 代表アルゴリズム | 線形回帰 /XGBoost/CNN | K-means/t-SNE/AutoEncoder | Q-learning/Policy Gradient |
| 評価指標の例 | 精度・F1・RMSE | シルエット係数・再構成誤差 | 累積報酬・収束速度 |
| ビジネス活用例 | 需要予測・スパム判定 | 顧客セグメント分析 | 広告入札戦略・ロボット制御 |
| 主なメリット | 精度を定量的に改善しやすい | 新たな発見・前処理に有効 | 長期的最適化・自律学習 |
| 導入時の課題 | ラベル作成コスト | 結果解釈の難易度 | 報酬設計・環境シミュレーション |
教師あり学習:ラベル付きデータで精度を担保
教師あり学習は、入力データに正解ラベルを付けてモデルを訓練し、未知データに対する予測精度を高める方法です。
回帰(数値予測)と分類(カテゴリー判定)の2系統が中心で、売上予測やスパム判定などラベルが明確なタスクで力を発揮します。十分な量と質のラベル付きデータがそろえば、評価指標の改善サイクルを短く回せる点が魅力です。
一方で、データ作成コストやラベル付与の主観性がボトルネックになる場合があり、データガバナンス体制の整備が欠かせません。
参考:自己教師あり学習とは?基礎やビジネス活用方法まで一挙解説|LISKUL
教師なし学習:隠れた構造やパターンを発見
教師なし学習はラベルのないデータを入力とし、クラスタリングや次元削減などによって潜在的な構造を抽出します。
顧客セグメントの発見や異常検知の前処理として用いることで、新たな知見を得たり後続の教師ありモデルを効率化したりできます。
評価指標を設定しにくいことや、得られた結果の解釈に専門知識が必要な点が課題ですが、ラベル作成が難しい領域で価値を生む有力なアプローチです。
参考:教師なし学習とは?仕組み・メリット・活用事例を非エンジニア向けに解説|LISKUL
強化学習:行動の最適化を自律的に学習
強化学習はエージェントが環境との相互作用から報酬を受け取り、試行錯誤を通じて最適な行動方針(ポリシー)を学習します。
製造ラインの自動制御や広告入札戦略など、連続した意思決定が求められるタスクで採用が進んでいます。
報酬設計やシミュレーション環境の構築に工数がかかるものの、実環境での実験コストを抑えながら高いパフォーマンスを引き出せる点が強みです。
運用フェーズでは安全制約やリアルタイム性を考慮したハイブリッド設計が鍵となります。
モデルの学習で使われる代表的アルゴリズム5つ
モデルの学習では「どのアルゴリズムを選ぶか」が精度と開発コストを左右します。
本章ではビジネス活用で採用例の多い5つのアルゴリズムの特徴を紹介します。まず概要をつかみ、次章のデータ準備や環境選定にどう結びつくかをイメージしてください。
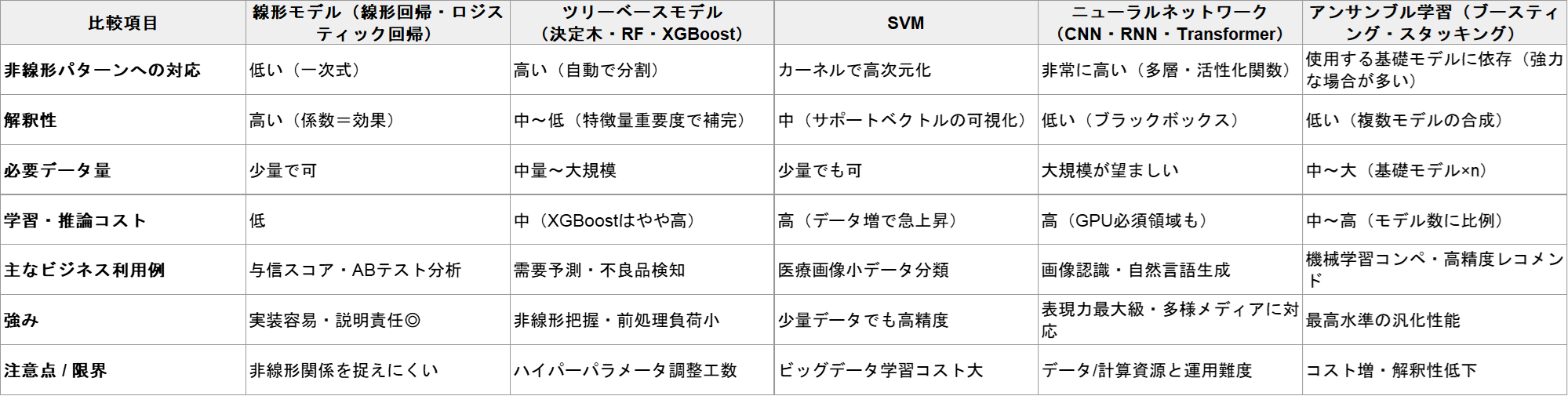 ※クリックで拡大できます
※クリックで拡大できます
1.線形モデル(線形回帰・ロジスティック回帰)
線形モデルは入力と出力の関係を一次式で表現するシンプルな手法です。パラメータ数が少なく解釈性が高いため、施策の効果検証や与信モデルなど説明責任が求められる領域で重宝します。
特徴量と目標変数の関係がほぼ線形であれば、複雑な手法に比べ迅速に実装できるうえ過学習のリスクも低い点が利点です。
反面、非線形パターンを捉える力に限界があるため、複雑なデータ構造には後述のツリーモデルやニューラルネットワークが選択肢に上がります。
2.ツリーベースモデル(決定木・ランダムフォレスト・XGBoost)
ツリーモデルはデータを条件分岐で細かく分割しながら規則性を学習します。
単体の決定木は過学習しやすい一方、ランダムフォレストやXGBoostといったアンサンブル化により高精度とロバスト性を両立できます。
カテゴリー変数の前処理が少なくて済み、非線形な関係も自動的にキャプチャできるため、需要予測や不良品検知など多様な特徴量を持つタスクで優位性があります。
ただし大規模データでの学習時間やハイパーパラメータ調整の負荷が増える点は計画時に考慮が必要です。
3.サポートベクターマシン(SVM)
SVMはマージン最大化という概念でクラス間を分離し、カーネルトリックにより高次元空間でも線形分離可能にするアルゴリズムです。
少量データでも比較的高い汎化性能を得られるため、医療画像の分類などデータ収集が困難な領域で採用されています。
一方、データ量が増えるにつれ学習時間とメモリ消費が急増するため、ビッグデータ用途ではツリーモデルやディープラーニングに置き換わるケースが多く見られます。
4.ニューラルネットワーク(CNN・RNN・Transformer)
ニューラルネットワークは多層の重み行列を通じて複雑な非線形関係を学習する枠組みで、画像・音声・テキストなど高次元データの処理に強みを発揮します。
特にConvolutional Neural Network(CNN)は画像認識、Recurrent Neural Network(RNN)やその発展形は時系列解析、そしてTransformerは自然言語処理や生成AIで成果を上げました。
大量データとGPU/TPUなどの演算資源を前提とするため、クラウド活用やMLOps基盤の整備が精度向上と運用安定の鍵になります。
5.アンサンブル学習(スタッキング・ブースティング)
アンサンブル学習は、複数モデルを組み合わせて最終予測を出力することで、個々のモデルの弱点を補完し全体の汎化性能を底上げするアプローチです。
ブースティング系(XGBoost、LightGBM)は弱学習器を順に学習させ誤差を縮小し、スタッキングは異なるアルゴリズムをメタモデルで統合します。
精度面では極めて強力ですが、モデル数に比例して学習・保守コストが増え、解釈性も低下しやすい点がトレードオフとして存在します。ROIを鑑み、重要KPIのみアンサンブル化するといった優先順位づけが実務的です。
データ準備と特徴量エンジニアリング
モデルの精度はアルゴリズム選択以上に、入力データの質と特徴量の設計で決まります。
本章では「なぜデータ前処理が欠かせないのか」「どのように特徴量を作り込むか」を体系的に整理し、再現性の高いワークフローを描けるようにします。
データ品質がモデル精度を左右する理由
データに欠損や誤記が混在すると、学習済みモデルはノイズまでパターンとして覚えてしまい、本番投入後の精度低下を招きます。
逆に、外れ値を適切に扱い統計的な分布を整えるだけで、アルゴリズムを変更せずとも評価指標が大幅に向上することは少なくありません。
したがって、データ品質の担保は「後工程のチューニングを楽にする投資」と位置づけて計画段階で工数を確保することが重要です。
前処理の基本ステップ――欠損値・外れ値・スケーリング
欠損値は単純補完(平均値・中央値)か、モデルベース補完(kNN・回帰)かをタスク特性で選択します。
外れ値はIQRやzスコアで検知し、ビジネスインパクトを考慮して削除かWinsor化を判断します。
続いて特徴量同士のスケール差をならすため正規化・標準化を実施し、傾向の異なる変数が一部に過度な影響を与えることを防ぎます。
ここまでの処理をパイプライン化し、データ更新時も同一ロジックが再現されるようコード管理することが望まれます。
特徴量エンジニアリングの代表手法
構造化データでは、カテゴリ変数のエンコーディング(One-Hot・Target Encoding)や日時変数の分解(曜日・四半期)によってモデルの可読性を高めます。
数値変数は対数変換や区分化により分布の歪みを緩和し、非線形アルゴリズムでなくてもパターンを捉えやすくします。
テキストや画像を扱う場合は、TF-IDF、Word2Vec、画像の統計量などを派生させることで、表現力を追加できます。
これらの操作をドメイン知識と統計的手法の両面から検討することで、過学習を抑えつつ説明変数の情報量を最大化できます。
自動特徴量生成と最新ツールの活用
近年はFeature StoreやAutoMLの台頭により、特徴量の設計・共有・バージョン管理を半自動化する環境が整っています。
たとえばGoogle Vertex AIやAWS SageMaker Feature Storeは、生成した特徴量をオンライン/オフライン双方で再利用できるため、モデルごとに同じ計算を繰り返す非効率を排除できます。
また、Deep Feature Synthesisなどの自動生成手法は時系列データのラグや集約を機械的に作成し、人手では探索しきれない組合せを発見する助けになります。
ツール選定では、既存パイプラインとの親和性とガバナンス要件(アクセス権限・監査ログ)を考慮し、ROIを見極めましょう。
学習環境の選択肢4つ
モデルの学習環境は「どこで計算を回すか」「誰が運用を担うか」に直結し、コスト構造・開発速度・セキュリティ要件まで大きく左右します。
本章ではオンプレミスからクラウド、さらに近年注目されるマネージドMLOpsやエッジ/ハイブリッドの4つの環境を紹介します。
1.オンプレミス環境:設備投資と専有性のトレードオフ
自社データセンターにGPUサーバーを設置するオンプレミスは、ハードウェアを完全に専有できるため機密性の高いデータや厳格なコンプライアンス要件に適しています。
長期利用を前提とすれば時間当たりコストは抑えられますが、初期CAPEXが高く設備更新も自社負担となる点がネックです。
また、ピーク時以外のリソース遊休や冷却・電力コストが財務を圧迫しやすく、TCOを正確に試算した上で導入可否を決める必要があります。
2.クラウドIaaS/PaaS:柔軟なスケールと従量課金
AWS、Azure、Google CloudなどのクラウドIaaSは、GPUインスタンスを数分で立ち上げられるため、PoCや季節変動のある学習ジョブと相性が良好です。
スポットインスタンスを組み合わせればコスト最適化も図れます。一方、長時間ジョブや常時稼働が前提のワークロードでは、従量課金がオンプレより高くつくケースがあります。
リージョン選定やデータ転送コストを含め、総額を試算したうえでスケール戦略を策定しましょう。
3.マネージドMLプラットフォーム:MLOpsの自動化と標準化
AWS SageMaker、Google Vertex AI、Azure Machine LearningといったPaaS型プラットフォームは、学習・推論・パイプライン管理・モデル監視をワンストップで提供します。
インフラ構築を抽象化できるため、データサイエンティストはアルゴリズム改善に集中でき、再現性と監査ログも自動確保されます。
ただしベンダーロックインとランタイム制約が付きまとうため、社内の既存CI/CD基盤やガバナンス方針と整合をとることが導入の成否を分けます。
4.エッジ/ハイブリッド:遅延・通信コストを抑える分散設計
製造ラインの装置や小売店舗の端末など、リアルタイム推論を要するシーンでは、クラウドで学習したモデルを軽量化(蒸留・量子化)してエッジデバイスで実行するハイブリッド構成が有効です。
センシティブなデータをローカル処理できるため、通信量削減とプライバシー保護を両立できます。
課題はデバイス毎のハード制約と運用統制であり、モデルのバージョン管理とOTA(Over-the-Air)アップデート体制が必須になります。
精度向上と過学習防止のポイント4つ
モデルは学習データに忠実すぎると未知データで性能が落ち込む一方、汎化ばかり意識すると十分な精度を得られません。
この章では「高精度」と「汎化性能」の両立を図るための代表的な手法を紹介します。
1.クロスバリデーションで汎化性能を可視化
学習データを複数のフォールドに分割し、交互に検証用データとして用いるクロスバリデーションは、データの偏りを平均化しモデルの汎化性能を安定的に測定できます。
特にデータ量が限られる場合、単一のホールドアウト検証では指標がばらつきやすいため、k-foldを採用して平均スコアと分散をあわせて評価することで、過学習の兆候を早期に発見できます。
2.正則化とドロップアウトでモデルを引き締める
パラメータ数が多いモデルは学習データのノイズまで吸収しがちです。
L1/L2正則化により重みをペナルティで抑制すると、必要以上に複雑な決定境界の形成を防げます。
ディープラーニングではドロップアウトが代表的で、学習時にランダムにニューロンを無効化することでネットワークの依存関係を分散し、汎化性能を向上させます。
正則化係数は小さすぎると効果がなく、大きすぎるとアンダーフィットを招くため、検証データでチューニングが必須です。
3.データ増強とサンプルバランシング
入力データにランダムな変換を施してバリエーションを増やすデータ増強(画像の回転・テキストの同義語置換など)は、モデルを多様な入力に慣れさせることで過学習を抑制します。
また、クラス不均衡がある場合は、オーバーサンプリングやアンダーサンプリング、あるいは適切なクラス重み設定により、少数クラスの学習不足を解消することが重要です。
これらは前処理段階の工夫として比較的低コストで取り組め、精度改善効果も高い施策です。
4.早期停止とモデルチェックポイントで過学習を防ぐ
学習エポックを重ねるほど訓練誤差は小さくなりますが、検証誤差が増え始めた時点が過学習の境界です。
検証誤差が一定回数連続で改善しなければ学習を打ち切る「早期停止」を導入すると、リソース消費を抑えつつ最適なエポックでモデルを保存できます。
併せて、ベストな検証スコアを記録した時点の重みをチェックポイントとして保存し、リリース時には最良モデルを確実にデプロイする体制を整えましょう。
コストとROIを最適化する方法
モデル開発は学習フェーズのGPU費用だけでなく、データ整備、継続的チューニング、推論基盤まで含めた総コスト(TCO)を把握しなければ投資効果が見えません。
この章では「コストを可視化 → 削減余地を特定 →ROIを高める」という順序で、意思決定に直結する実務フレームを解説します。
コスト構造を数値化し意思決定の軸をそろえる
最初に、データ取得・前処理・学習・推論・保守の各工程で発生する費用を洗い出し、固定費と変動費に分類します。
たとえばGPU時間は変動費、オンプレ設備償却は固定費という具合です。これをダッシュボード化し、部門間で単位コスト(例:1,000推論あたり円)を共有すると、改善効果が定量的に議論できるようになります。
学習コストを抑える3つの施策
- スポット/プリエンプティブルインスタンスを活用し、耐停止性の高いジョブを低単価で実行する
- モデルの蒸留・量子化でパラメータを圧縮し、学習時間とメモリ消費を削減する
- 転移学習やファインチューニングを採用し、既存モデルの重みを再利用してフルスクラッチ学習を避ける
これらを組み合わせるだけで学習費用を数十%カットできるケースが多く報告されています。
推論コストの最適化とSLAバランス
推論は常時リクエストが来るわけではないため、コンテナの自動スケールやサーバーレス推論(AWS Lambda+GPU対応)を使い、アクセスが閑散な時間帯のリソースを縮退させます。
さらに、バッチ処理できる業務はオフピークにまとめることで、ピーク時の同時起動数を抑えられます。
リアルタイム性が不可欠なAPIと、遅延許容度が高いバッチを分離して設計することが鍵です。
ROIを最大化する指標設計と運用サイクル
開発前に「モデルが改善すれば直接どのKPIがどの程度動くか」を仮説立てし、精度向上率と収益影響額をリンクさせます。
運用後は、精度指標だけでなくビジネス指標(例:転換率、在庫削減額)を継続的に計測し、投資回収期間をモニタリングします。
モデルの再学習タイミングはROIが下振れした時点をトリガーにし、過度な再学習でコストが膨らまないようガードレールを設定しましょう。
投資判断ガイドライン
下記の手順を組織的な標準プロセスに落とし込み、改善サイクルを継続して回すことで、モデル投資の費用対効果を安定的に最大化することが期待できます。
- まず「学習・推論それぞれの単位コスト」を算出し、損益分岐点を明確にする
- 精度向上施策は「費用1円あたり利益増額」が高い順に着手する
- インフラ変更はPoCで効果とリスクを検証後に本番移行する
- 経営層には「モデル刷新の意思決定をROI指標でシンプルに報告」し、予算承認プロセスを迅速化する
モデルの学習に関するよくある誤解5つ
最後に、モデルの学習に関するよくある誤解を5つ紹介します。
1.データ量を増やせば必ず精度が向上する
データ量と精度は必ずしも相関関係にあるわけではありません。確かに少量より多量の方がモデルは傾向を捉えやすいものの、品質が伴わなければノイズも同時に学習します。
重複レコードや誤入力を除去し、情報量の高い特徴量を追加する方が、単純なデータ増強より遥かに効果的なケースが多いのが実情です。
2.テスト精度が高ければビジネス価値も高い
評価指標の向上は重要ですが、意思決定に使うKPIと連動しなければ利益に直結しません。
たとえばF1スコアが数ポイント伸びても、顧客ライフタイムバリューや在庫圧縮額が動かないなら投資回収は見込めません。精度とビジネス指標をセットでモニタリングする体制が必須です。
3.深層学習を採用すればどの課題も解ける
ディープラーニングは画像・音声・自然言語で突出した性能を示しますが、構造化データの中規模タスクではツリーモデルの方が精度と説明性のバランスに優れる場合も多々あります。
モデル選定は課題特性、データ量、実装コストを総合的に比較したうえで行うべきです。
4.学習が終わればモデルは放置できる
データ分布が変わると既存モデルの推論が急激に劣化する「概念ドリフト」が発生します。
継続的モニタリングと再学習トリガーの自動化を組み込まなければ、精度を維持できずROIが下落します。運用フェーズこそ長期的なコスト管理の要となります。
5.成功事例の手法を真似すれば自社でも成果が出る
公開事例やコンペ優勝コードは学習環境やデータ構造、評価基準が異なることが大半です。手法をそのまま転用すると、前提が崩れて再現性が得られません。
まずは自社データを小規模に検証し、ビジネス要件に合うようカスタマイズするプロセスが欠かせません。
まとめ
本記事では、モデルの学習(Training)の基本概念から、実務で成果を出すための具体的なプロセス・手法・環境選定・コスト管理までを一挙に解説しました。
モデルの学習とは、データに潜むパターンを抽出し、自動で意思決定を支援する仕組みを構築する工程です。その成否を左右するのは、課題定義・データ整備・アルゴリズム選択・運用モニタリングという5つのステップを漏れなく回せるかどうかに尽きます。
学習手法には教師あり・教師なし・強化学習があり、目的変数の有無や意思決定の連続性で適材適所を見極める必要があります。さらに、線形モデルやツリーモデル、ニューラルネットワークなど代表的アルゴリズムの強み・弱みを踏まえれば、過不足のないモデル選定が可能です。
精度向上を狙うなら、データ品質の担保と特徴量エンジニアリングが最優先課題です。クロスバリデーションや正則化による過学習防止を組み込みつつ、データ増強やサンプルバランシングで入力の多様性を確保しましょう。
学習環境はオンプレミス、クラウド、マネージドサービス、エッジ/ハイブリッドから選択肢が広がっています。セキュリティ要件とTCOを比較し、短期PoCはクラウド、長期運用はハイブリッドなど段階的な導入が現実的です。加えて、スポットインスタンスや転移学習を活用すれば学習コストを抑えつつROIを底上げできます。
ポイントとしては「精度指標=ビジネス価値」ではないことを理解することが重要です。モデルがKPIにどのように貢献するかを定量的にモニタリングし、価値が下振れしたタイミングで再学習や施策見直しを即断できる体制こそが、長期的な競争優位につながります。
これからモデル活用を拡大したい企業は、まず小規模データで仮説検証し、成功パターンをスケールさせるアプローチから始めてみてはいかがでしょうか。
生成AIサービス20選を一覧で比較(2025年版)
生成AIは日々のアップデートが急速で、ChatGPT、Claude、Gemini以外に業務特化の専門的な生成AIも増えてきました。
今回、今注目しておくべき生成AIツールを用途別に20個選出し、一覧表にまとめた資料をご用意しました。
サービス名・提供企業料金・AIごとの特徴・セキュリティ・利用されている分野など、一覧で比較できます。
- 導入検討の初期段階で候補を絞るとき
- 特定業務に適したツールを比較・整理するとき
- アップデートが追えていないので、一次整理を短縮したい
- 社内説明や稟議の補助資料として利用するとき
など、目的に応じてご活用ください。
特にChatGPT、Calude、Geminiについては種別(ROI改善や工数削減、リスク低減など)の導入効果事例をまとめており、利用シーンに応じた判断の補助として活用できるよう構成されています。
無料で取得できますので、ぜひお手元にダウンロードしてみてください。

